第 6 章 爬虫技术
6.1 基础准备
6.1.1 环境和安装
1.下载安装docker desk官网
win10用户需要注意一个操作系统的坑。
Win10的专业版用户(professional version),可以直接安装docker desk。但是也需要需要启用hyper-V 虚拟服务。可以ctrl+shift+delete查看cpu性能,能看到是否已经启用。具体启用办法:进bios –> system security,记得按F10确认启用。(ps. 2020版win10开始有了性的服务支持,主要是liniux模块的加入,可以进一步提升docker的运行性能。)
Win10家庭版用户(home version)不支持docker desk,只能使用安装Install Docker Toolbox官网下载
2.下载安装TightVNC用于查看实时交互。
下载安装TightVNC用于查看实时交互。官网。一份说明供学习:Debugging Using VNC
3.Rstudio安装RSelenium包。
6.1.2 docker设置
1.注册docker hub账号。(此步骤可忽略)。
2.配置国内镜像站点。速度明显改观!docker desk软件里设置修改:
"RegistryMirror": [
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com"
]如果是Docker toolbox则需要修改配置文件C:\Users\<user>\.docker\machine\machines\default\config.json
6.1.3 TightVNC配置
第一步,docker命令行,拉取chrome。
$ docker run --name chrome -v /dev/shm:/dev/shm -d -p 4445:4444 -p 5901:5900 selenium/standalone-chrome-debug:latest以上命令主要内容是,创建chrome实例,并分别打开两类端口。其中第一类端口4445:4444是分配给chrome通信;第二类端口5901:5900是分配给下面的TightVNC通信。
第二步,配置TightVNC Viewer【注意:不是server】。
端口:127.0.0.1:5901 【option 里面要设置port为5901】
密码:secret6.1.4 docker常用操作
1.docker命令拉取selenium -chrome镜像。
标准模式:
$ docker run -d -p 4445:4444 selenium/standalone-chrome
诊断模式:
$ docker run -d -p 4445:4444 selenium/standalone-chrome-debug
$ docker run -d -p 5901:5900 -p 192.168.31.135:4445:4444 --link http-server selenium/standalone-chrome-debug
2.docker常见操作参看资料
3.Docker与jave version的匹配
查看java 版本。参考。
$ docker exec 【containerId】 java -version
Docker 设置jave_home环境变量。参考
$ docker ENV JAVA_HOME /path/to/java
6.2 正则表达Regex
一些有用的学习教程和文档:
Regex Cheat Sheet。参看rexegg.com网站教程](https://www.rexegg.com/regex-quickstart.html#lookarounds)
regular-expressions.info。参看网站教程
6.2.1 常见规则表达
下面列出一些常见问题:
任意中文字符:具体请参看
[1] "中" "文"指定出现次数:具体请参看参看
?, ??: 0 or 1 occurrences (??is lazy,?is greedy)*, *?: any number of occurrences+, +?: at least one occurrence{n}: exactly n occurrences{n,m}: n to m occurrences, inclusive{n,m}?: n to m occurences, lazy{n,}, {n,}?: at least n occurrence
例子:
To get “exactly N or M”, you need to write the quantified regex twice, unless m,n are special:
X{n,m} if m = n+1
(?:X{n}){1,2} if m = 2n
中文半破折号:通过regex查找替换
(\d{4})-(\d{4}) 替换为 \1—\26.3 CSS基础
6.3.1 CSS selector
| 类型 | 含义 | 子类 | 语法 | 示例 |
|---|---|---|---|---|
| Simple selector | ID | # | #para1 { } | |
| class/name | . | .center{ } | ||
| Attribute selector | [ ] | |||
| Universal Selector | * | * { } | ||
| Grouping Selector | , | h1, h2, p { } | ||
| Combinator selector | relationship | Descendant | space | div p { } |
| Child | > | div > p { } | ||
| Adjacent sibling | + | div + p { } | ||
| General sibling | ~ | div ~ p { } | ||
| Pseudo -class selector | state | Mouse over/ visited link/focus | : | a:link {} |
| Pseudo -element selector | part | First letter/ line/ element | :: | ::first-line { } |
| Insert content before or after | :: | p::after { } |
6.4 RSelenium
RSelenium包在CRAN的官方文档
常用的操作,可以参考中文教程。
下面列出一些常碰到的爬虫场景和处理办法。
6.4.1 两种抓取流程
流程A:调用电脑本地浏览器进行抓取。适合简单的、静态的、无需验证登陆的网页内容抓取。如下,将直接调用本地Firefox浏览器进行抓取。
library("RSelenium")
driver <- rsDriver(browser=c("firefox"), port = 4447L)
remDr <- driver[["client"]]
remDr$maxWindowSize()
remDr$open()流程B:采用docker进行封装式抓取。适合复杂的、交互的、需验证登陆的动态网页内容抓取。如下,将调用docker下的chrome浏览器进行抓取。
library("RSelenium")
#-------part 01 start docker + RSelenium-------
# 1. run docker service and container
#### you should run and start docker desktop first.
#### then run code in 'window power shell': docker run --name chrome -v /dev/shm:/dev/shm -d -p 4445:4444 -p 5901:5900 selenium/standalone-chrome-debug:latest
# 2. create the remote driver
### 'window power shell': ipconfig
remDr <- RSelenium::remoteDriver(remoteServerAddr = "localhost",
port = 4446L,
browserName = "chrome")
remDr$open()6.4.3 批量抓取文本
经验法则:首先,定位html
node有两种办法。一是单个node定位的remDr$findElement()用法;二是多个node定位的remDr$findElements()用法。这个区分务必要重视,不能混淆或粗心错用。其次,关于多个命令操作的连续使用,只会操作第一个node内容,例如remDr$findElement()$getElementText()和remDr$findElements()$getElementText()都只会得到第一个定位到的node元素的文本内容。
方案1:findElements下进行loop循环抓取。对于大批量的抓取处理,可能耗时会比较长。
xpath_tar <- "//ul[@id='table_pf']//*//div[@class='u-jgjc-time']"
elements <- remDr$findElements("xpath", xpath_tar)
out <- NULL
for (i in 1:length(elements)) {
elems <- elements[[i]]
out[i] <- elems$getElementText() %>% unlist()
}方案2:findElements下采用lapply语法抓取。对于大批量的抓取处理,可以一定程度上提升效率,节约时间。可参看网络问答。
6.4.4 在浏览器窗口之间进行自由切换
具体见github issue社区互动 参考
myswitch <- function (remDr, windowId)
{
qpath <- sprintf("%s/session/%s/window", remDr$serverURL,
remDr$sessionInfo[["id"]])
remDr$queryRD(qpath, "POST", qdata = list(handle = windowId))
}
Sys.sleep(1)
windows_handles <- remDr$getWindowHandles()
Sys.sleep(1)
#remDr$switchToWindow(windows_handles[[2]])
myswitch(remDr = remDr, windowId = windows_handles[[2]])6.4.6 选择不可见的勾选框
参考网络问答
对于一些网站,有时候存在肉眼不可见的网页元素。具体图示如下:
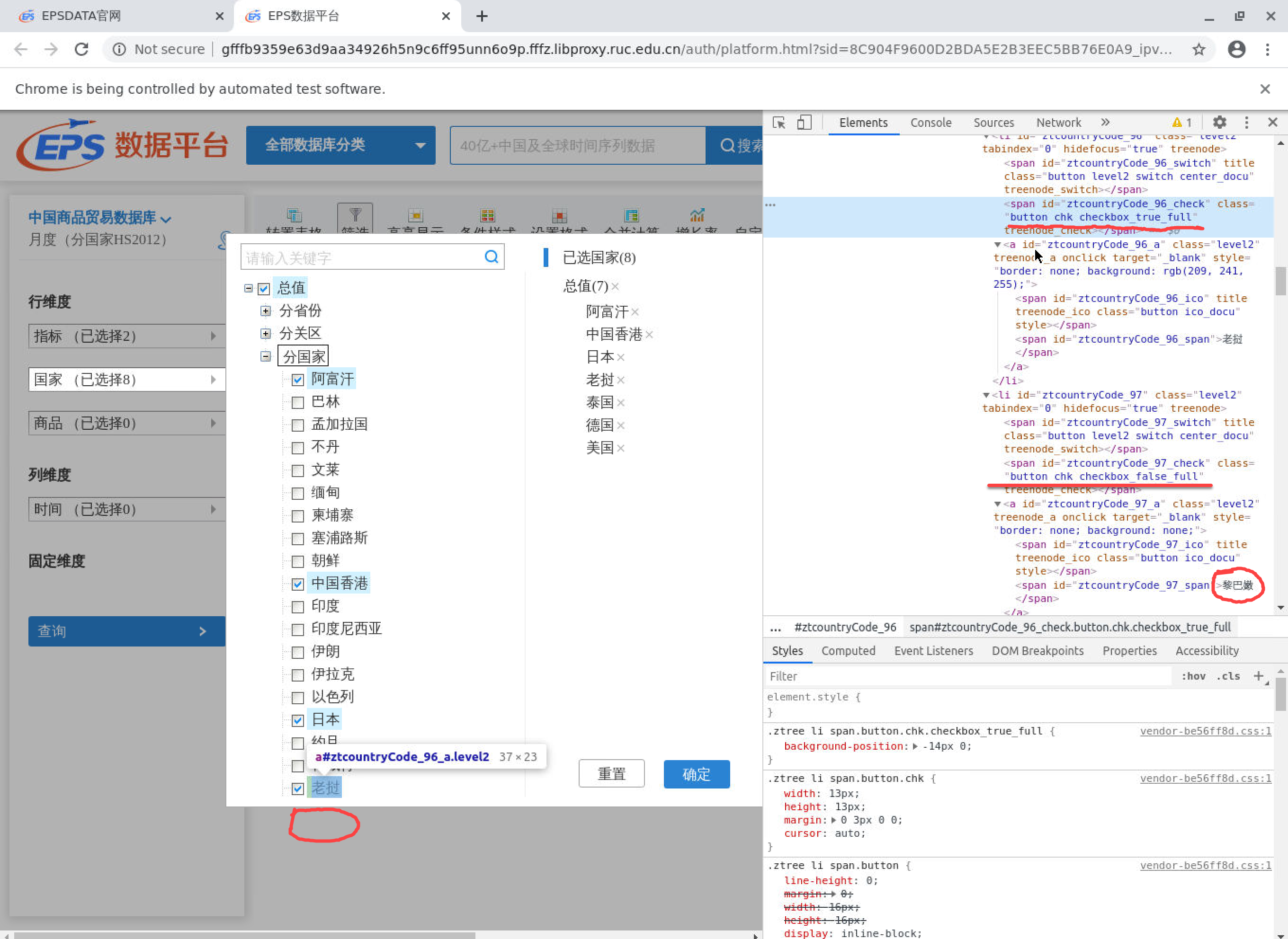
图 6.1: 一个示例
这时,我们需要使用remDr$executeScript()函数来执行java操作。
6.4.7 日历和下拉菜单操作
日历输入框选择,存在多种形式:
可以直接输入年月日的文本输入框(input box)。一般情况下,可以直接使用
RSelinium的命令remDr$findElement(using = "xpath", value = xpath_tar)$sendKeysToElement(list("2017-01-01"))。需要进行JavaScript鼠标事件的文本输入框(js input),datepicker。例如,价格数据网站的日期选择(商务部价格信,农副产品,日度数据,日期选择框)。此时,可以通过执行JavaScript命令,进行日期选择(可参看队长问答)。
# method 2 js direct
## see https://stackoverflow.com/questions/57330068/issue-with-datepicker-rselenium
xpath_tar <- "//*[@id='nr2_searchDate']"
## excutive js
js <- paste0("document.querySelector('#nr2_searchDate').value='", date_tar,"';")
remDr$executeScript(js)
## click to search
xpath_tar <- "*//div//div[@class='ycljt']//input"
remDr$findElement(using = "xpath", value = xpath_tar)$clickElement()参考资料:
6.4.8 悬置鼠标唤出下级菜单
见示例。
6.5 动态抓取技术
6.5.1 安装工具软件
下载安装docker 官网
- 一个教程供学习:A Docker Tutorial for Beginners
Rstudio中安装RSelenium包 官网
下载安装TightVNC用于查看实时交互。官网
- 一份说明供学习:Debugging Using VNC
6.5.2 docker配置准备
注册docker hub账号(非必须)
配置国内镜像站点(强烈建议)。速度将明显改观!具体参看材料
使用docker命令拉取selenium -chrome镜像(请根据自己的浏览器选择,chrome或者firefox)
在Rstudio的Terminal窗口中执行如下命令!
- 启动docker服务:
$ docker run -d -p 4445:4444 selenium/standalone-chrome6.5.3 RSelenium相关操作
使用RSelenium包控制浏览器主要依靠remoteDriver系列函数。简单操作命令如下。可参考网络材料
6.5.4 一个实例:抓取并下载智慧教学云平台资料
案例数据抓取的目标:
目标是获得全部视频(83x3= 249)的下载地址。
整理各个视频的基本信息,用于下载视频后期的准确重命名(下载地址url是一串字符而已)。
登录后的目标页面:
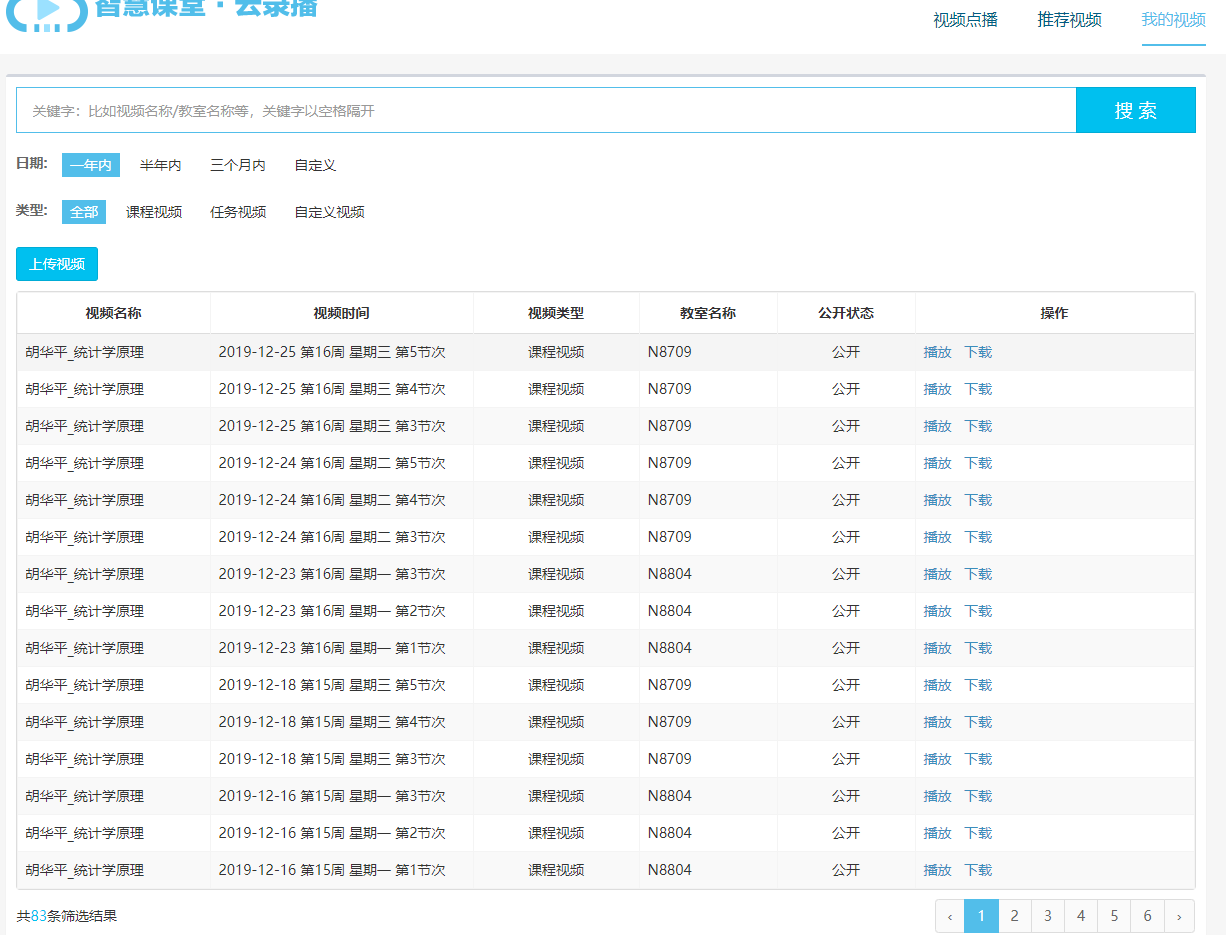
案例数据抓取的特点:
需要账号/密码登陆
动态网页:可能会碰到JavaScript、下拉选择等操作
网站可能随时调整:例如视频材料定期清除
6.5.4.1 R代码实现
# useful packages
library(RSelenium)
library(wdman)
library("XML")
library("tidyverse")
library(xml2)
library(rvest)
# remote driver
remDr <- RSelenium::remoteDriver(remoteServerAddr = "localhost",
port = 4445L,
browserName = "chrome")
remDr$open()
# navigate to the website of interest
remDr$navigate("http://172.26.3.11:8080/")
# check on there
remDr$screenshot(display = TRUE)
# login info
remDr$findElement("id", "username")$sendKeysToElement(list("your-id"))
remDr$findElement("id", "password")$sendKeysToElement(list("your-password"))
remDr$findElement("css", ".login-aside input[type='submit']")$clickElement()
# check again
remDr$screenshot(display = TRUE)
# click my video
remDr$navigate("https://ylb.nwafu.edu.cn/ICloudRecordPlay/teacherVideoManagement")
# click one year (avoid random jump)
remDr$findElement(using = "css", "#body > div.mod-filter > dl:nth-child(1) > dd > a:nth-child(1)")$clickElement()
# click page 2
remDr$findElement(using = "css", "#body > div.bootstrap-table > div.fixed-table-container > div.fixed-table-pagination > div.pull-right.pagination > ul > li:nth-child(3) > a")$clickElement()
remDr$screenshot(display = TRUE)
# set page number css (number 1 begin with par 2)
page_total <- 6
page_css <- paste0("#body > div.bootstrap-table > div.fixed-table-container > div.fixed-table-pagination > div.pull-right.pagination > ul > li:nth-child(", 1:page_total+1, ") > a")
# set download page (click "下载")
item_total <- 15
pos <- paste("#courseTable > tbody > tr:nth-child(", 1:item_total,") > td:nth-child(6) > a:nth-child(2)", sep ="")
pageinfo <- NULL
#----- page loop --------
for (i in 1:5){
# click one year (avoid random jump)
#remDr$findElement(using = "css", "#body > div.mod-filter > dl:nth-child(1) > dd > a:nth-child(1)")$clickElement()
# set chromeDriver window size (very important! for page number >3)
remDr$setWindowSize(1600, 900)
# click the page number(number 1 begin with par 2)
remDr$findElement(using = "css", page_css[6] )$clickElement()
# wait load page
Sys.sleep(2)
remDr$screenshot(display = TRUE)
# look for table element
tableElem <- remDr$findElement(using = "id", "courseTable")
# Html output
txt <- tableElem$getElementAttribute("outerHTML")[[1]]
# scrape the date and room
v_date <- txt %>% read_html() %>% xml_nodes("tbody") %>% xml_nodes("td:nth-child(2)") %>% xml_text()
v_room <- txt %>% read_html() %>% xml_nodes("tbody") %>% xml_nodes("td:nth-child(4)") %>% xml_text()
# tidy data.frame
info_tem <- data.frame(date=v_date, room =v_room)
#----- loop for download url-------
url <- NULL
for (i in 1:8 ){
# click and open window
remDr$findElement(using = "css", pos[i])$clickElement()
Sys.sleep(1)
#remDr$setImplicitWaitTimeout(milliseconds = 10000)
remDr$screenshot(display = TRUE)
# look for download element
downElem <- remDr$findElement(using = "css", "#downloadVideo-modal > div > div")
txt_down <- downElem$getElementAttribute("outerHTML")[[1]]
# get attributes
url_down <- txt_down %>% read_html() %>% xml_nodes("div >div > a") %>% xml_attr("href")
# close the float window
remDr$findElement(using = "css", "#closePicResourceDetail-modal > span")$clickElement()
url_tem <- t(data.frame(url_down)) %>% as_tibble()
url <- rbind(url, url_tem)
}
pageinfo_tem <- bind_cols(info_tem, url)
pageinfo <- bind_rows(pageinfo, pageinfo_tem)
}
# close drivers
remDr$getStatus()
remDr$closeWindow()
# tidy data
pageinfo_ok <- pageinfo %>%
gather(key = "VideoAngle", value = "url", V1:V3) %>%
separate(col = "date" , into = c("date","week", "weekday", "slot"), sep = " ") %>%
arrange(date, week, weekday, slot,room) %>%
mutate(VideoRole= recode(VideoAngle,"V1"="teacher","V2"="student", "V3"="slide")) %>%
mutate(exist= if_else(url=="javascript:void(0)", "NO", "YES")) %>%
mutate(week.en = str_c("week",str_extract(week, '[:digit:]')),
slot.en = str_c("slot",str_extract(slot, "[:digit:]"))) %>%
#mutate( weekday.en =weekday) %>%
mutate(weekday.en =recode(weekday, "星期一"="1", "星期二"="2","星期三"="3",
"星期四"="4","星期五"="5")) %>%
mutate(weekday.en =str_c("weekday",weekday.en)) %>%
mutate(dir= str_c(
str_c(date, week.en, weekday.en, slot.en, VideoRole, sep="-"),
".mp4")
)
# export file
xlsx::write.xlsx2(pageinfo_ok, "page-info-ok.xlsx")6.6 APACHA验证
APACHA是一种人机验证机制,对于网络爬虫而言,大家更熟悉的是网站采用APACHA机制来设置“防爬虫”门槛,也即各类验证码、滑块验证。这种验证机制比较成熟和严谨,应用场景十分广泛。如何有效识别和破解成为现实一大难题。
实际上视觉识别已经发展到多个领域,包括图片标记、面孔和地标检测、光学字符识别 (OCR)等。
6.6.1 传统的tesseract识别包
tesseract包专门用于从图片中提取文本github repo。
优点:独立算法,简单快速,本地即可运行,无需联网。
缺点:算法比较老旧,识别准确率不太高。
具体代码示例如下:
6.6.2 google vision 云平台API
google cloud platform 提供了Vision API,可以完成各类视觉识别任务。
优点:识别技术强大,识别准确率高。
缺点:(国内)需要网络和网速支持。另外就是有使用量的限制,需要支付结算进行扩容使用量。
R用户的具体实现:
1.申请google vision API接入授权。具体:
登陆google开发者控制台(Google’s developer console)进行申请和授权。
创建project,并申请开通Vision的API服务。
设置
OAuth 2.0客户端和OAuth同意屏幕。
2.下载安装RoogleVision包(github repo)。
具体代码示例如下:
#install.packages("RoogleVision", repos = c(getOption("repos"), "http://cloudyr.github.io/drat"))
if (!require("devtools")) {
install.packages("ghit")
}
devtools::install_github("cloudyr/RoogleVision")
library("RoogleVision")
### plugin your credentials
options("googleAuthR.client_id" = keyring::key_get("id", keyring = "gg-vision2"))
options("googleAuthR.client_secret" = keyring::key_get("secret", keyring = "gg-vision2"))
## use the fantastic Google Auth R package
### define scope!
options("googleAuthR.scopes.selected" = c("https://www.googleapis.com/auth/cloud-platform"))
googleAuthR::gar_auth()
#Basic: you can provide both, local as well as online images:
txt <- getGoogleVisionResponse(imagePath="pic/zhuyun/valid-img-gray.png", feature="TEXT_DETECTION",numResults = 1)6.7 API接口调用
6.7.1 Google cloud translation
使用Google cloud translation平台的必备条件:
注册谷歌账号。
完成结算支付设置(国际结算支付,如国际信用卡或贝宝PayPal)。
创建Google cloud translation项目(project)。
完成项目认证和密钥准备。需要将私钥下载为.json文件保存到本地电脑。
项目密钥准备:
方法一:需要将私钥下载为.json文件保存到本地电脑。
方法二:
id为project id(项目 ID);token为API密钥:my project \(\Rightarrow\) API和服务 \(\Rightarrow\) 凭据 \(\Rightarrow\) API密钥 \(\Rightarrow\) 显示密钥。
使用注意事项:
下面为演示代码:
# minimal example
txt <- "One way to interpret the CEF $m(x)=\\mathbb{E}[Y \\mid X=x]$ is in terms of how marginal changes in the regressors $X$ imply changes in the conditional expectation of the response variable $Y$."
txt[1] "One way to interpret the CEF $m(x)=\\mathbb{E}[Y \\mid X=x]$ is in terms of how marginal changes in the regressors $X$ imply changes in the conditional expectation of the response variable $Y$."translateR::translate可以翻译dataframe的某列,也可以翻译vector(见下例):
# translate the vector
library(keyring)
library(translateR)
result <- translateR::translate(
content.vec = txt,
google.api.key = list(
key=keyring::key_get(
"token",
keyring = "your-auth-keyring")
),
source.lang = "en",
target.lang = "zh-CN") googleLanguageR只能翻译vector文本对象(见下列):
# translate with google translate API
#renv::install("ropensci/googleLanguageR")
library(googleLanguageR)
# add google authentic
gl_auth("C:/your-path/google-authen.json")
result <- gl_translate(
t_string = txt,
target = "zh-CN")$translatedText参看资源:
- 免费在线书籍 APIs for social scientists: A collaborative review, Chapter 12 Google Translation API,具体 参看
6.8 调用XHR爬取json
总体而言,为了实现自动化爬取网络数据,我们已经有两个朴素的思路和工具:
其一是直接简单模拟式爬取,也即模仿人类正常访问并爬取数据。主要工具集是“黄金搭档”
docker + Selenium的组合使用。其最大的优点是完全模拟人类正常访问,基本可以爬取任意我们能访问的站点数据。然而,其缺点也同样明显:多种工具相互依赖性、爬取链条比较长、需要编写更多的特殊定制函数(大大增加编程工作量)、代码很难具有复用性(每次抓取都要独立编写程序)。其二是直接接口参数化爬取,也即调用网站的API接口,进行参数化查询和爬取。主要工具集是
rvest + XML的组合使用。其最大的优点是参数化、批量化查询,爬取效率高,获得的数据更加准确。其缺点在于:不是所有的站点都提供API查询接口(要么比较隐蔽,要么就要收费),高价值API查询接口都有自己特定的安全机制和参数设定,有一定的学习成本。
其中,利用服务器的XHR结果,我们也可以实现快速的接口参数化爬取。
6.8.1 XHR爬取基本过程
步骤1:查看目标网站是否支持API接口式XHR查询json。以火狐浏览器(firefox)为例 :
右键“检查” 进入开发工具窗口
点击“网络”
刷新网址
点击选择“XHR”
点击选择服务器返回的正确json文件(类型json,状态200,方法GET)
右键“在新标签页中打开”/或者点击选择“消息头”查看GET下的json文件实际地址。
步骤2:探索并确定查询参数和调用方式。最终的目标是系统化地获得json文件的实际url地址(见步骤1的最后一步)。需要注意的是:国内一些网站会使用中文作为参数字符,因而需要首先转换为标准网址URL码值参数。例如,我们可以使用utils::URLencode()函数进行快速URL码值转换:
原始显示报头地址(不能直接访问):http://aboc.agri.cn/priceSelect/stateList?tableName=PRICE_WITH_STATE&category=蔬菜&page=1&addr=西安市&platform=&name=&pageSize=200
码值转换后的真实查询地址(可以进行访问):http://aboc.agri.cn/priceSelect/stateList?tableName=PRICE_WITH_STATE&category=%E8%94%AC%E8%8F%9C&page=1&addr=%E8%A5%BF%E5%AE%89%E5%B8%82&platform=&name=&pageSize=200
查询地址补齐。对于公开的API查询,一般都是采用
http://的非加密方式进行访问,有时候不添加这一个信息可能导致无法访问。进一步地,预览查看时,浏览器的选择也会比较重要。例如,谷歌浏览器chrome会认为非加密访问是不安全的而影响预览,而火狐Firefox则对非加密访问会更宽容一些。
步骤3:利用R网页爬虫工具包(包括rvest、xml2、httr、logr等)获得查询结果,然后再利用jsonlite::fromJSON()和tibble()等方法将json数据格式转换为标准的dataframe数据集。
考虑在线爬取会报错(可能原因包括网络状态不好、返回信息集过大等),可以进行相对更稳定的两步走策略:也即先查询并下载服务器返回信息,然后再转换数据格式(
json转dataframe)。其中尤其关键的是第一步,我们需要用到:httr::GET(url_tar, httr::timeout(60))来控制查询返回的时长;read_html() %>% html_text()来保存查询结果。为了备查备忘,我们可以创建日志文件:
logr::log_open(tem)和logr::log_print(inf_out)
步骤4:如果数据集比较大,则需要使用SQL工具包(包括DBI、dbplyr、RSQLite)等构建结构化查询数据库(sql)。
准备数据库:事先严格定义好数据集变量及格式类型。例如将定义好的空数据集事先写入到数据库表单中去:
DBI::dbCreateTable(mydb, tbl_tar,df_na)。写入数据库:爬取过程中将查询结果循环迭代续写(append)添加到数据库中。例如续写命令
DBI::dbWriteTable(conn = mydb, name = tbl_tar, value = tbl_json, append=TRUE, overwite=FALSE);又例如循环控制命令for (i in 1:100) {your scrape procedure}。
步骤5:对于超大数据集爬取,为了提升爬取效率(花费更少的时间),可能会用到平行运算方法。可能用到的R工具包包括:parallel。(我们会单独说明这一方法。)
6.8.2 XHR爬取示例(价格数据)
示例网页:西安市农业农村局价格行情(官网)
抓取任务为:完成网站中全部市场类别价格数据的整体性抓取。
示例参数集为:批发市场;显示35条信息。
示例API查询地址为:http://114.67.197.232/web/api/market/pageByPriceInfoVo?marketId=1&page=1&isSell=0&scName=&size=35
上述json地址链接可以获得全部后台查询信息:
status 200
message "OK"
data
records […]
total 200341
size 35
current 1
searchCount true
pages 5725
ok true经过初步查询,可以发现如下系统参数规律:
url_p1 <- "http://114.67.197.232/web/api/market/pageByPriceInfoVo?marketId="
page <- 1
n <- 35
par_site <- tibble(
marketType = c("批发市场","零售市场",
"产地价格","农资价格"),
marketEng = c("wholesale","retailsale",
"spotmarket","inputmarket"),
marketId = c("1", "1", "3", "4"),
isSell = c("0", "1", "","")
) %>%
mutate(url = paste0(
url_p1, marketId,
"&page=", page,
"&isSell=", isSell,
"&scName=",
"&size=", n)
)6.9 并行运算
6.9.1 代码示例(zoningr)
并行运算涉及到比较复杂的计算机知识,这里以我开发的开源R包zoningr为例(github仓库huhuaping/zoningr)。
zoningr包主要是实现对中国城乡区划的统计编码数据实现抓取,并提供抓取后的各层级数据集(地市级city、区县级district、乡镇街道级street和村组居委会级neighbor)。
多核并行抓取的R代码可参看我的github仓库huhuaping/zoningr:
[1] 8# make cluster
cl <- makeCluster(4)
# import external pkgs
clusterEvalQ(cl, {
require(magrittr)
require(tidyverse)
require(rvest)
require(httr)
require(glue)
require(stringr)
})
# external function or dataset
clusterExport(cl, "tbl_city")
clusterExport(cl, "get.tbl")
K <- 10
tot <- nrow(tbl_city)
page <- ceiling(tot/K)
# now run parallel computing
## note: this process will be failed
## if your internet has low speed or is not stable.
s <- parLapply(cl, 1:page, get_par)
check <- s[[1]]6.10 pdf转rmarkdown文本
6.10.1 路线图
pdf文件可以通过多种方式进行创建,其中通过LaTex方式编译得到的pdf是一种比较传统的方式,也是最方便于转换为Rmd/qmd格式,准确率会大大提高。
对于任意可读取的pdf文件,R包
pdftools可以进行逐行读取和解析。缺点在于:丢失pdf的大纲结构;识别正确率完全取决于文本内容的复杂程度。R包
tmcd82070/tex2rmd可以对.tex格式存放的LaTax pdf源文件进行格式转换(.Rmd/.qmd格式)。因为掌握了pdf的编译源文件,理论上可以通过编程方式完美转换。缺点:一般很难拿到某个.pdf文件对应的.tex源文件。不过目前出现了一些基于机器学习的pdf识别工具(例如mathpix sniping tool,见官方链接),可以在较高精度上将其先智能识别为.tex格式。
三步走战略:原始pdf \(\Rightarrow\) coded text \(\Rightarrow\) recognized text
需要识别内容:
正常文本(导航标签、正文)
公式符号(公式环境和行内公式)
表格
工具集及主要方法:
R包
pdftools(见github repo)R包
tmcd82070/tex2rmd(见github repo)
6.10.2 获取pdf导航标签信息
如果pdf存在导航标签,则可以使用pdftools::pdf_toc()函数得到目录页(toc)
#download.file("http://arxiv.org/pdf/1403.2805.pdf", "data-raw/pdf/1403.2805.pdf", mode = "wb")
# Table of contents
toc <- pdf_toc("data-raw/pdf/1403.2805.pdf")
# Show as JSON
text_json<- jsonlite::toJSON(toc, auto_unbox = TRUE, pretty = TRUE)
# json style
y_list <- jsonlite::fromJSON(text_json)
# pure list
y_list_new <- map_if(y_list, is.data.frame, list)
# flatten tibble
y_df_new <- as_tibble(y_list_new) %>%
unnest(title,names_repair = tidyr_legacy) %>%
unnest(children, names_repair = tidyr_legacy) %>%
unnest(children, names_repair = tidyr_legacy) %>%
unnest(children, names_repair = tidyr_legacy,
keep_empty = T) %>%
select(tidyselect::matches("title\\d{1}", perl =T))6.11 html抓取
6.11.1 html表格抓取
常用的R包包括:
rvest包。很厉害的html表格抓取包。unpivotr包(see github nacnudus/unpivotr)。实现对多层次表头的xlsx表格进行正确读取(不丢失表头信息)。htmltab包(see github crubba/htmltab)。允许对多层次表头的html表格的进行指定抓取(不丢失表头信息)。
6.11.2 html非标准表格
当html表格呈现出rowspan/colspan的跨行/跨列单元格时,简单地进行rvest抓取表格可能会不可行。具体看如下案例。
library("tidyverse")
# ====files html path====
## the web url is
## files_path <- "https://www.yidaiyilu.gov.cn/xwzx/roll/77298.htm"
files_path <- "data-raw/html/list-contract-year-2021.html"
Year <- as.numeric(str_extract(files_path, "(\\d{4})"))
# ====xpath table====
xpath_tbl <-"//*[@id='zoom']/div[4]/div[1]/table"
#=== table header=====
my_header <- c("region", "country", "news","glapse", "guidance")方案1(成功):rvest+修改。(see reference “Read html tables with cells spanning on multiple rows”blog)
# see reference
## "Read html tables with cells spanning on multiple rows" [blog](https://www.scitilab.com/post_data/read_table/2019_09_11_readtable/)
library(rvest)
# get the lines of the table
lines <- files_path %>%
read_html() %>%
html_nodes(xpath=xpath_tbl) %>%
html_nodes(xpath = 'tbody/tr')
#define the empty table
ncol <- lines %>%
.[[1]] %>%
html_children()%>%
length()
nrow <- length(lines)-1
table <- as.data.frame(matrix(nrow = nrow,ncol = ncol))
names(table) <- lines[[1]]%>%
html_children()%>%
html_text()%>%
gsub("\n|\t| ","",.)
# fill the table
for(i in 1:nrow){
# get content of the line
linecontent <- lines[[i+1]]%>%
html_children()%>%
html_text()%>%
gsub("\n|\t| ","",.)
# get the line repetition of each columns
repetition <- lines[[i+1]]%>%
html_children()%>%
html_attr("rowspan")%>%
ifelse(is.na(.),1,.) %>% # if no rowspan, then it is a normal row, not a multiple one
as.numeric
#select only free columns
colselect <- is.na(table[i,])
# repeat the cells of the multiple rows down
for(j in 1:length(repetition)){
span <- repetition[j]
if(sum(colselect)>1){
table[(i):(i+span-1),colselect][,j] <- rep(linecontent[j],span)
}else{table[(i):(i+span-1),colselect] <- rep(linecontent[j],span) }
}
}方案2(不可行):rvest包跨行合并读取失败。
tbl_raw <- read_html(files_path,encoding = "UTF-8") %>%
html_nodes(xpath = xpath_tbl) %>%
html_table(header = T, fill = F,trim = T) %>%
.[[1]] %>%
as_tibble() %>%
# rename
rename_all(.,~my_header) %>%
mutate_all(., str_trim, side = "both")方案3(不可行):htmltab中文乱码
6.11.3 html字符编码
正确查明html页面的字体是极为关键的。基本操作是通过诸如chrome浏览器查看html代码的头信息(),查看encoding编码设定。
然而有时候也会出现依据encoding编码的设定,但是抓取后还是出现字体乱码的情形。其中的一个潜在可能是字符集编码存在包含性关系。
例如编码集
Shift_JIS大于编码集Shift_JISX0213,尽管html页面设置为编码集charset=Shift_JIS,但实际抓取解码则应该采用charset=Shift_JISX0213。可以通过chrome浏览器查看html页面的报文信息确认这一点(具体为Network \(\Rightarrow\) Headers \(\Rightarrow\) Response Headers \(\Rightarrow\) Content-Type:text/html;charset=utf-8)。可以参看Stack Overflow问答:r - Investigating encoding error。对于中文编码集,也可能出现类似情形,例如html页面设置为编码集
charset=gb2312,但R抓取是也要注意,可能需要设置encoding ="GB18030"。可以参看统计之都的讨论:编译包中文乱码自定义编码问题。
下面给出一个html中文抓取实例。目标是抓取示例网页的名单:关于公布第二批农业产业化国家重点龙头企业名单的通知。
虽然html页面头信息表明是gb2312,但实际上需要设置为GB18030才能正确被read_html()解码识别!
6.11.4 html元素本地修改
目标对象的少量html元素不标准,会大大影响抓取代码的效率。此时可以直接使用Rstudio编辑器对本地html文件进行源代码修改,保存后再进行元素抓取。
实例1:抓取名单。关于公布第五批农业产业化国家重点龙头企业名单的通知。三处存在html代码异常情形,例如,“东乌珠穆沁旗草原东方肉业有限责任公司鄂尔多斯市四季青农业开发有限公司”,应该是两家公司,需要分别设定
<p></p>。
<p class="MsoNormal" style="margin: 7.5pt 0cm; text-indent: 24pt; line-height: 190%; text-align: left; font-size: 16px;" align="left"><span lang="EN-US" style="font-size: 16px; line-height: 190%; font-family: ˎ̥;"> </span><span style="font-size: 16px; line-height: 190%; font-family: 宋体;">内蒙古蒙都羊业食品有限公司</span></p>
<p class="MsoNormal" style="margin: 7.5pt 0cm; text-indent: 24pt; line-height: 190%; text-align: left; font-size: 16px;" align="left"><span lang="EN-US" style="font-size: 16px; line-height: 190%; font-family: ˎ̥;"> </span><span style="font-size: 16px; line-height: 190%; font-family: 宋体;">东乌珠穆沁旗草原东方肉业有限责任公司鄂尔多斯市四季青农业开发有限公司</span></p>
<p class="MsoNormal" style="margin: 7.5pt 0cm; text-indent: 24pt; line-height: 190%; text-align: left; font-size: 16px;" align="left"><span lang="EN-US" style="font-size: 16px; line-height: 190%; font-family: ˎ̥;"> </span><span style="font-size: 16px; line-height: 190%; font-family: 宋体;">扎兰屯市蒙东牲畜交易市场有限责任公司内蒙古民丰薯业有限公司</span></p>